

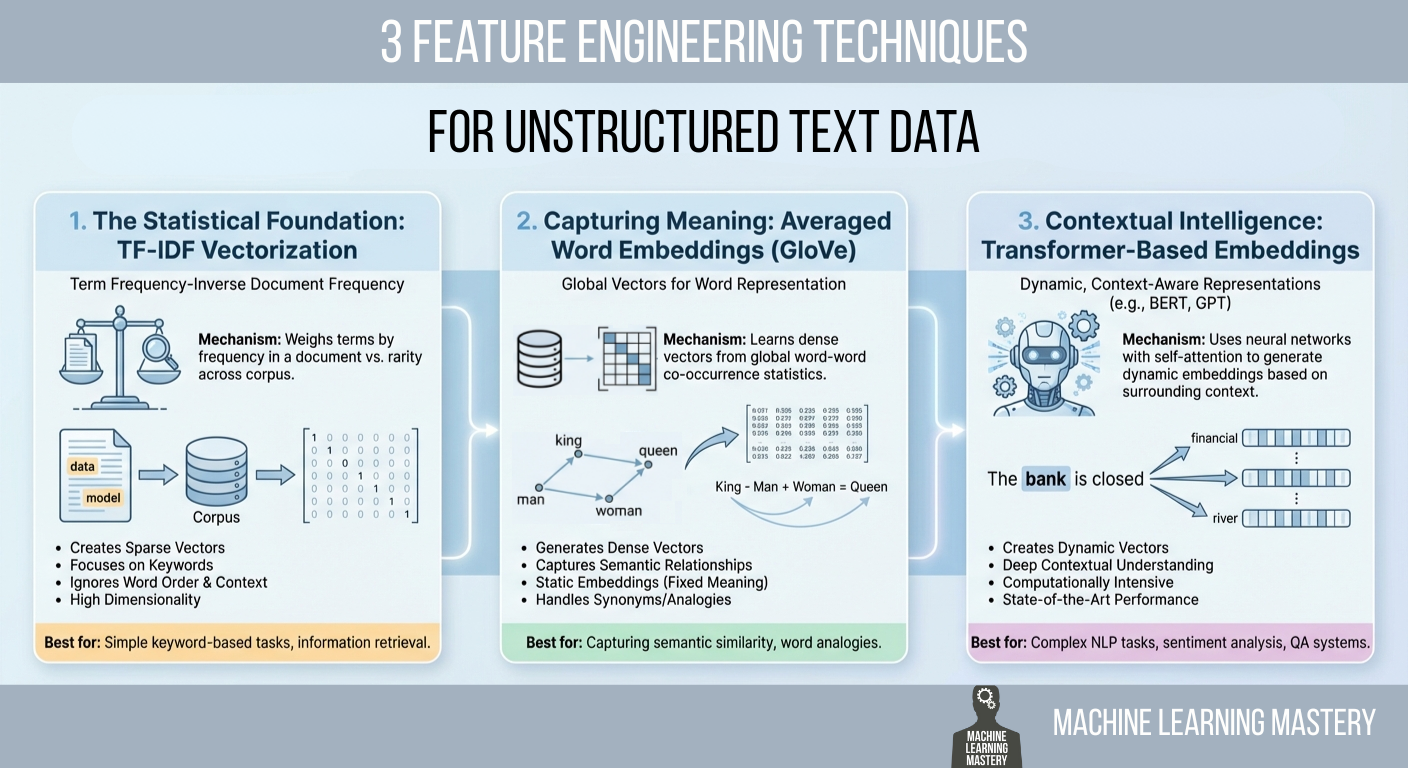


























Change to Apache Iceberg Could Streamline Queries, Open Data

The folks behind the Apache Iceberg project are considering making an architectural change to the specification in the next version that would allow query engines to access metadata directly from the Iceberg catalog, thereby avoiding the need to talk to the underlying object storage system. If implemented, the change–which mirrors in some way how the new DuckLake table format works–could have implications on how data is stored and retrieved in Iceberg-based lakehouses.
The way the Iceberg specification is currently written, the metadata that describes the Iceberg tables are stored in an on-disk format that is required to reside directly on the object storage, such as Amazon S3 or Google Cloud Storage (GCS). When a query engine, such as Apache Spark or Trino, submits a query, the REST-based metadata catalog (such as Apache Polaris) sends the engine a path that leads back to the object storage system to get the data.
“Normally when you read an Iceberg table, the first thing you do is you get a path from the catalog and it tells you where to read a set of snapshots,” Russell Spitzer, a principal engineer at Snowflake and a member of the project management committee (PMC) for both Apache Iceberg and Apache Polaris, explained. “You start reading your snapshot. That’s another file on disk that gives you a list of manifests and each manifest has a list of data files. And then from all of that, you eventually send out that information to your to your workers, and they start actually reading data files.”
Instead of storing just the top of the metadata tree within the REST catalog like Polaris, the change would allow the entire metadata tree to reside in the catalog. That would eliminate the need for the query engines to go back to the object storage system to figure out what data it needs, streamlining the data flow and reducing query latency.![]()
The existing architecture was built for a reason. For starters, object storage is infinitely scalable, so you would never run into a problem where you can’t fit all of your metadata inside of your catalog, Spitzer said. It’s also very easy for other clients to deal with. However, today’s query engines have more intelligence built in, and the extra layer of metadata storage and access really isn’t needed. That is leading the Iceberg and Polaris projects to explore how they could store more metadata in the catalog itself.
“One of the things that we want to move towards, or at least start thinking about, is how much of that can we cache at the catalog level?” Spitzer told BigDATAwire at the Snowflake Summit last week in San Francisco. “A of these systems, like Trino, Spark, and Snowflake, will have a coordination system that doesn’t need to actually know the nitty gritty of every data file that’s being read, because what they actually just need is to know what portions of data are they going to assign out to their workers. And then the workers can get that with a reference to the catalog and say, ‘Hey, I’m part of scan five. I’m supposed to read task four.’ And then those data file paths will get sent straight to the worker node instead of to the coordinator. So basically you optimize away that path.”
The good news is that the Iceberg specification already has an API for this. It’s called the scan API, and it allows query engines to access metadata directly from the REST catalog. That API had been described, but not actually developed. That development work is occurring right now, according to Spitzer. The new functionality could be part of Apache Iceberg version 4.
In addition to optimizing the path, bypassing the additional metadata layer on the object storage system could also allow users to export data directly from Iceberg lakehouses into other Iceberg lakehouses, Spitzer said.

Credits: DuckDB
“If you have a client that knows how to read these scan tasks that are produced, you don’t actually need the underlying table to be in that representation. You just need to know how to read it into that on the on the catalog side, so the client doesn’t have to be familiar with all sorts of different table formats,” Spitzer said. “The client just needs to know how the Iceberg Rest spec communicates, and then you can basically have support for all types of different table formats in your catalog transparently to your users, with no conversion of the metadata. You just give them different sets of Parquet data files.”
Enabling direct access to table format metadata and avoiding the need for a single root file that controls access to data is one of the features in the newly released DuckLake offering from DuckDB. DuckLake, which describes a new table format and a lakehouse architecture, adopts a SQL database to manage metadata, which is something that DuckDB’s Mark Raasveldt and Hannes Mühleisen talked about at length in a blog post.
Spitzer acknowledged that similarities between the proposed Iceberg changes and DuckLake. “It was interesting to me when Duck Lake was announced just a little while ago, because we’re already thinking about these ideas,” he said. “I was like, okay I guess that’s validation that what we’re thinking about is what other folks are thinking about too.”
If the new approach is implemented, it would likely be optional, according to Spitzer, and users would have the choice of allowing query engines to access metadata directly or use the existing approach.
Related Items:
DuckLake Makes a Splash in the Lakehouse Stack – But Can It Break Through?
How Apache Iceberg Won the Open Table Wars
The Open Optimism of Apache Polaris
The post Change to Apache Iceberg Could Streamline Queries, Open Data appeared first on BigDATAwire.










