

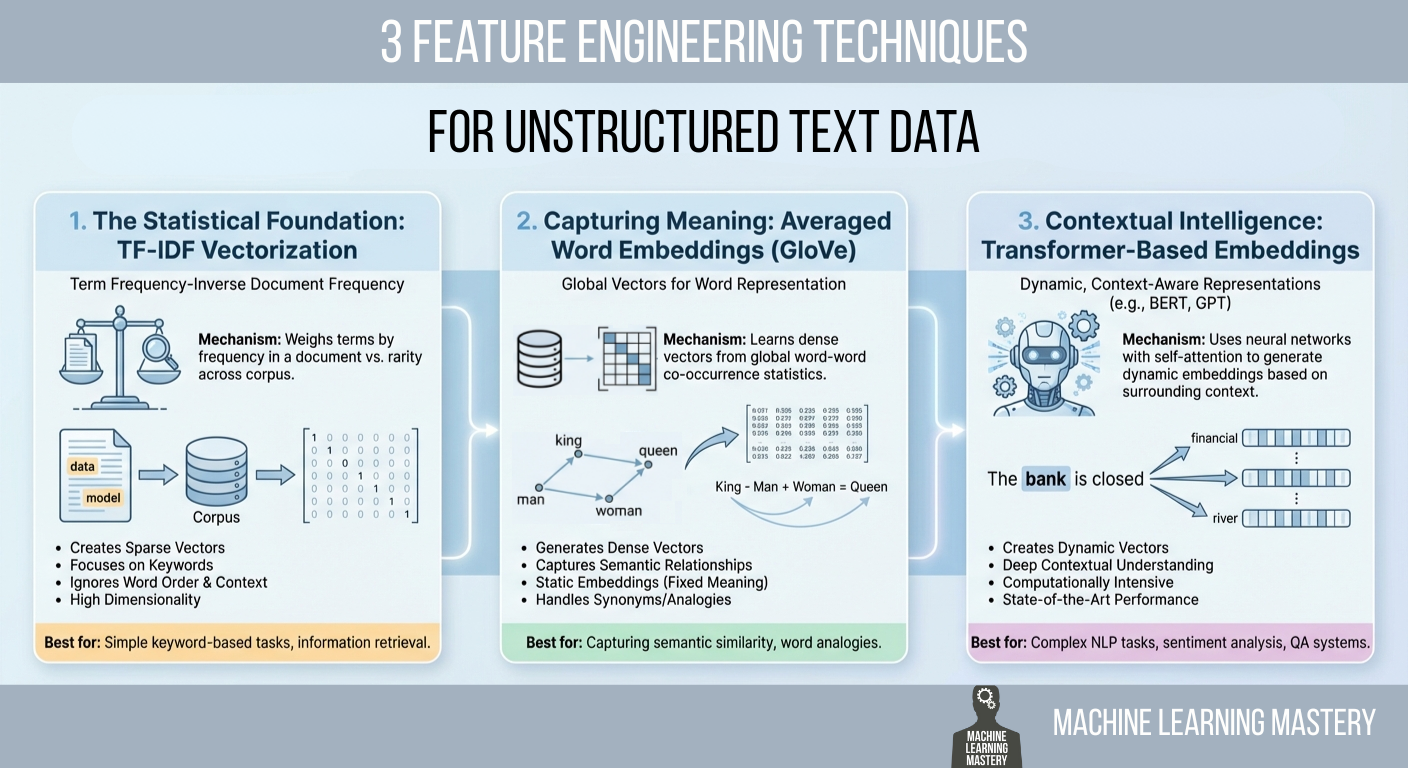


























DuckLake Makes a Splash in the Lakehouse Stack – But Can It Break Through?

DuckDB, the creators of the embedded analytics engine of the same name, have stirred the data world with a bold rethink of lakehouse architecture. The company has unveiled DuckLake, a new open table format designed to simplify lakehouses by using a standard SQL database for all metadata.
Instead of following the current trend of layering JSON and Avro metadata files on blob storage, DuckLake consolidates all metadata into a standard SQL database. It tracks table changes, schema updates, and data statistics using simple SQL transactions – no extra catalog services or custom APIs needed. This makes it more reliable, faster, and easier to manage, according to DuckDB.
To understand what makes DuckLake disruptive, we have to go back to last year, when Databricks acquired Tabular, the company founded by the original creators of Apache Iceberg, for a staggering $1 billion. The move signaled a major consolidation in the open table format space, as Databricks already owned Delta Lake.
Many believed that this would be the beginning of the consolidation of power around open table formats. After all, both Iceberg and Delta Lake were built to solve similar problems of making object-storage-based data lakes behave more like databases. They have become a sort of de facto standards for big data platforms that need reliable ways to update, query, and manage large datasets without losing consistency or accuracy.

Source: DuckDB
Just when it seemed like the industry was stabilizing around the Iceberg and Delta alignment, post the Tabular acquisition, DuckDB shook things up with DuckLake, proposing a much simpler approach to managing metadata and transactions in data lakes. While Iceberg and Delta Lake were specifically designed not to require a database, they ended up requiring one as a catalog backend to support transaction integrity. DuckDB is proposing that if you need a database anyway, why not just store all metadata there?
“Here at DuckDB, we actually like databases,” wrote DuckDB founders Mark Raasveldt and Hannes Mühleisen in a blog post. “They are amazing tools to safely and efficiently manage fairly large datasets. Once a database has entered the Lakehouse stack anyway, it makes an insane amount of sense to also use it for managing the rest of the table metadata.”
“We can still take advantage of the ‘endless’ capacity and ‘infinite’ scalability of blob stores for storing the actual table data in open formats like Parquet, but we can much more efficiently and effectively manage the metadata in a database.”
Along with the innovative architecture, DuckLake also offers some new features. It supports multi-table transactions, which means users can make coordinated updates across several tables at once and be sure of the changes that are applied. That’s something even many large-scale data platforms struggle to do reliably.
Users can also query a table as it existed at a specific point in time. This can be useful for debugging, auditing, or simply recovering from accidental changes. By recording each change as a snapshot rather than overwriting previous versions, DuckLake ensures a reliable versioning system within the SQL catalog.
DuckDB emphasizes that DuckLake is built on the company’s core design principles of keeping things simple and incremental. The company claims users can run DuckLake on everyday devices, such as their laptops, by installing and using the DuckDB extension. The users can use the extension for testing, development, and prototyping.

Shutterstock
A key feature of DuckLake’s simplicity is making use of external storage systems. The DuckLake files are “immutable”, allowing the format to be integrated with any storage system like a local disk, local NAS, S3, Azure Blob Store, GCS, etc. DuckLake models all of it as simple relational tables, which means any standard SQL database that supports ACID (Atomicity, Consistency, Isolation, Durability) can be used to manage it.
“There are no Avro or JSON files,” the DuckDB founders explain. “There is no additional catalog server or additional API to integrate with. It’s all just SQL. We all know SQL. The DuckLake-internal table schema is intentionally kept simple in order to maximize compatibility with different SQL databases. Most organizations already have a lot of experience operating a system like that.”
Along with scalability, the format also aims to offer better speed. With fewer storage round-trips, metadata queries are centralized and executed within milliseconds in the catalog database. DuckLake is also designed to improve scalability by allowing multiple compute nodes to access shared storage and metadata efficiently.
Not everyone is convinced about DuckDB’s approach. Jack Ye, a software engineer at LanceDB, points out potential weaknesses. He wrote in a LinkedIn post that while he applauds the ambition behind DuckLake, he’s concerned that using SQL for metadata lacks the structured extensibility found in JSON-based standards. In his view, this could make it harder for different tools and systems to integrate cleanly, especially as the ecosystem grows.

Shutterstock
Some industry experts are of the opinion that the pain points being addressed by DuckLake have already been tackled by the Iceberg community and are in the process of being fixed through new APIs and aggressive caching strategies. There are also some concerns in the market that DuckDB’s openness could actually be a liability without proper guards. Nevertheless, DuckLake is generating some interest across the industry.
There is no doubt that Iceberg and Delta Lake are backed by major companies in the industry and remain dominant players. These tools are already deeply integrated into big data platforms, with widespread adoption and shared standards. However, DuckDB offers an alternative – one that challenges the complexity of today’s lakehouse stack.
Related Items
What the Big Fuss Over Table Formats and Metadata Catalogs Is All About
How Apache Iceberg Won the Open Table Wars
Apache Hudi Is Not What You Think It Is
The post DuckLake Makes a Splash in the Lakehouse Stack – But Can It Break Through? appeared first on BigDATAwire.








