Neo4j Cranks Up the Scaling Factor with New Infinigraph Architecture

Neo4j this week unveiled its new Infinigraph architecture that it says addresses one of the fundamental challenges in the scaling of graph databases: the difficulty in keeping a graph database’s structure in memory as the volume of data increases. The innovation will unleash new scale for operational use cases, such as fraud detection, and also bolster emerging GraphRAG workloads, the company says.
Thanks to the way they store data in connected nodes, graph databases are able to run some types of data-intensive workloads an order of magnitude more efficiently than traditional relational databases. Instead of performing compute-intensive joins to identify connections in a given data set–such as people who have worked with a particular company–a property graph like Neo4j’s can find the similarities with a simple query, since the data was originally modeled upon connections to begin with. In addition to getting answers quicker, graphs can save CPU cycles and power and expense that entails.
However, there are limitations to the graph approach. For starters, graph databases work best when the entire graph can be loaded into memory. That is not a problem for smaller data sets, but it becomes an issue as the size of the data grows. Neo4j was originally built to run on large symmetric multi-processor (SMP) scale-up machines with lots of memory. It started developing a distributed, scale-out version of its database about five years ago to address customers with very large datasets. While it made progress in the distributed world, the fundamental limitations in using graphs in a distributed architecture remain.
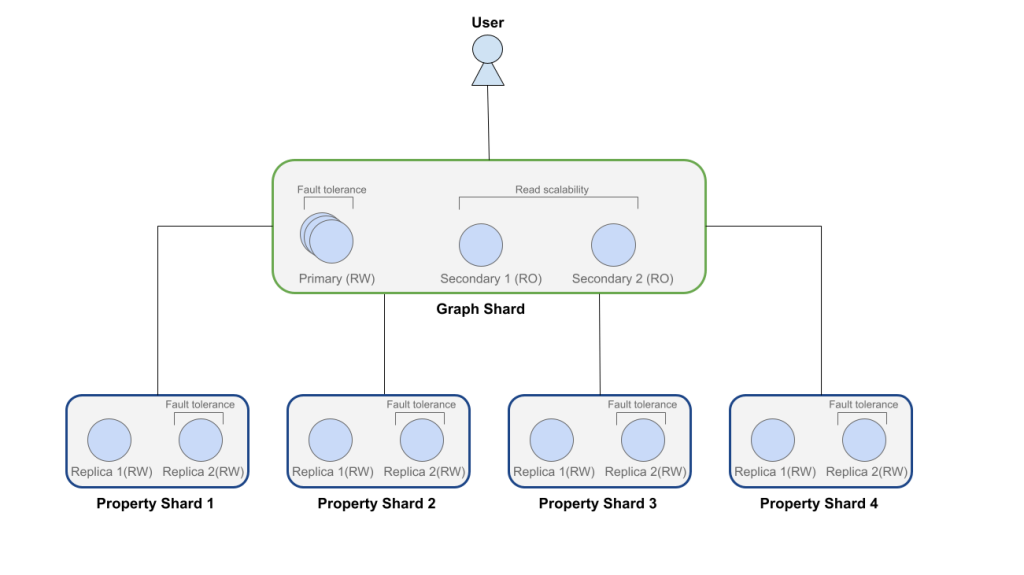
Infinigraph allows Neo4j to scale horizontally while keeping nodes and edges in memory (Image courtesy Neo4j)
Neo4j’s launch of Infinigraph represents an innovative solution to this dilemma. The company decided to compromise on the types of data that it separated to run on separate nodes, or sharded. Instead of splitting the core components of its property graph architecture–namely the nodes and relationships–and sharding them out to separate machines in a cluster, with Infinigraph, the company elected to shard only properties associated with the nodes and relationships, thereby keeping the nodes and relationships intact in the same memory space.
Properties in a graph database are the values associated with a node or a relationship. Each node or relationship can have any number of properties associated with it. For instance, a node for a “person” might have properties such as “name” or “age,” while the relationship component might have additional proprieties, like a specific date or location for a “WorksAt” property.
With Infinigraph, Neo4j is introducing property sharding, which enables the nodes and relationships to stay on a single server while the potentially voluminous properties are stored in separate nodes in a cluster, says Dan McGrath, Neo4j’s VP of product management for cloud.
“One of the great challenges in the database industry has been scaling transactional and analytical graph workloads without sacrificing performance, structure, or ease of use,” McGrath wrote in a blog post. “Infinigraph architecture solves this challenge by distributing a graph’s property data across the servers in a cluster. Property sharding allows the graph itself to remain logically whole; queries behave as expected, and applications scale without code changes or manual workarounds.”
According to McGrath, each entity in the Neo4j graph shard has exactly one corresponding entity in a property shard, and when a query requests properties, the system automatically fetches them from the right shard, while traversal stays local to the topology shard.![]()
“The whole system runs in an autonomous cluster,” he wrote. “The graph shard forms a regular Raft group, ensuring availability and failover. Property shards can be scaled independently by adding replicas, which provides them with high availability, a new feature introduced for property sharding in the Neo4j autonomous cluster.”
No changes are required to the graph database applications with Infinigraph, Neo4j says, and Cypher queries work as before. Nodes and relationships are written to the graph shard, while the specific properties of the nodes and relationships may be written to a different shard. The developer however is writing just a single query, and the database figures out which property shard to fetch the data from.
This approach brings many benefits, McGrath says, including the capability to scale a graph beyond 100TB of data; the capability to embed billions of vectors directly in the graph; eliminating the need for ETL pipelines; all while maintaining full ACID compliance.
Neo4j says this new approach will help teams conduct operational and analytic operations at the same time, including detecting fraud and analyzing fraud rings from the same dataset, or generating real-time customer recommendations while analyzing decades of customer data and behavioral trends. “They can power GenAI assistants, compliance systems, and transactional applications on one consistent source of truth,” the comapny says.
There are some limitations with the new approach, however. The number of property shards is fixed at creation in the first version of Infinigraph, and it doesn’t yet support automatic rebalancing. Neo4j recommends Infinigraph be used for property-heavy graphs.
Infinigraph is available now in Neo4j’s self-managed offering. It will soon be available in Neo4j AuraDB, the company’s cloud-native platform.
Related Items:
Neo4j Promises ‘No More ETL’ with Aura Graph Analytics
Neo4j Drives Simplicity with Graph Data Science Refresh
Neo4j Going Distributed with Graph Database
The post Neo4j Cranks Up the Scaling Factor with New Infinigraph Architecture appeared first on BigDATAwire.