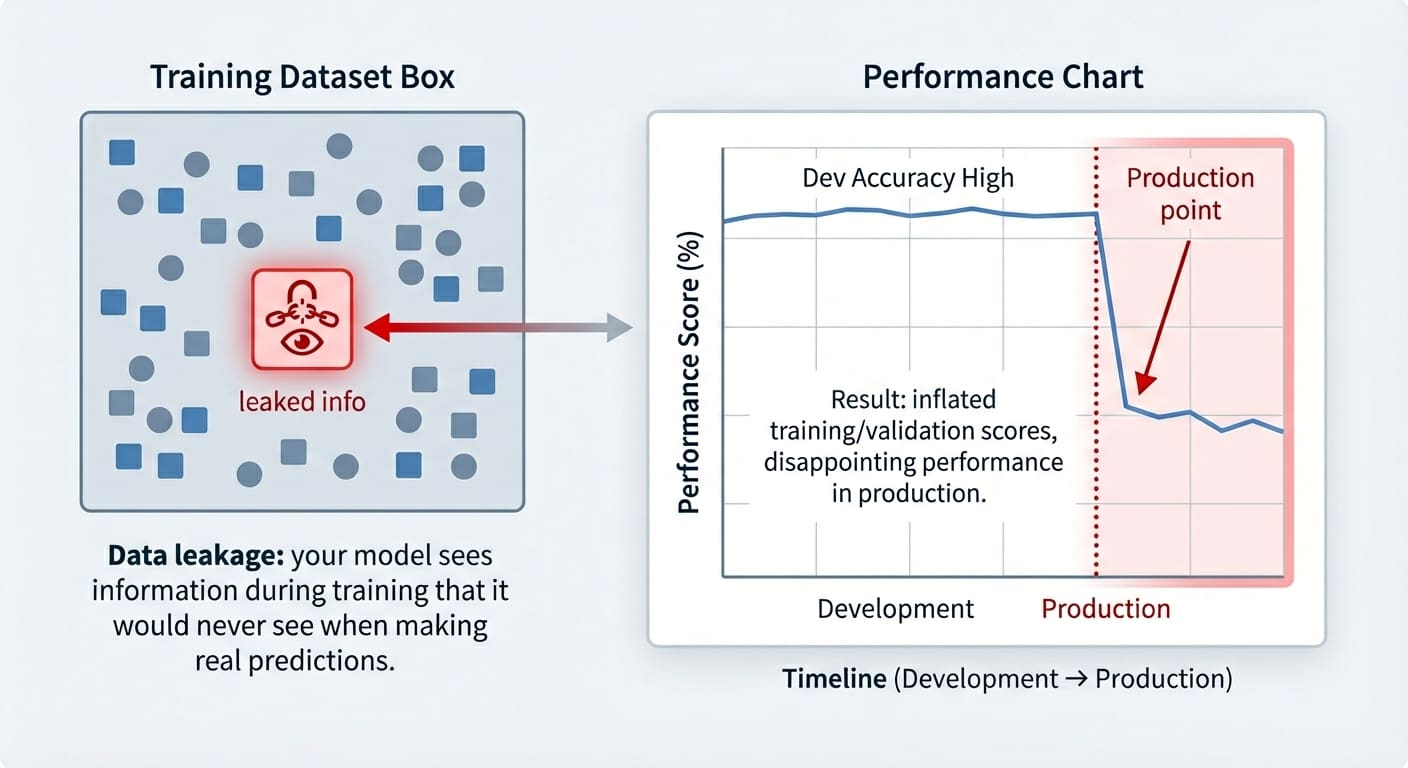


























This Big Data Lesson Applies to AI

There’s no shortage of hype when it comes to AI. We’re constantly bombarded with warnings that AI is about to change things forever, and that if we don’t implement AI now, we risk becoming failures. In many ways, the current climate resembles the early days of the big data boom. We learned some (painful) lessons from that episode, but do business leaders remember?
The technology sector moves very quickly and is prone to periodic fits of irrational exuberance. People of a certain age will recall the dot-com boom of the late 1990s, when the World Wide Web emerged and the commercialization of the Internet began. When those early, shaky business models didn’t pan out–pets.com, anyone?–investors fled, resulting in the dot-com bust of 2000 and a recession from 2001 to 2003.
The emergence of Web 2.0 (JavaScript, AJAX, etc.) later in the decade brought better tech, which helped create viable online business models. The launch of Facebook in 2005, AWS in 2006, and the iPhone in 2007 planted the seeds for the social media, cloud, and mobile phone revolutions that would soon sprout in all their glory.
By 2010, big data was the talk of tech town. Consumers equipped with better Web browsers and smart phones began generating massive amounts of data, while new scale-out cloud systems based on commodity X86 tech provided new ways to store and process it. Yahoo developed Hadoop in the image of Google’s internal tech while NoSQL databases (also a Google creation) began to emerge from the digital swamps of Silicon Valley, sending in motion a decade-long experiment in distributed computing.
Suddenly, every business needed to have a big data strategy. If you weren’t “doing” big data, we were told, you risked being eclipsed by a more nimble tech startup, or worse–your competitor down the street who went all in on big data. A climate of fear and greed took hold, and hundreds of billions of dollars were invested in new technology, with the hope that it would allow companies to “do” big data and win the day.
Pets.com sock puppet before the company imploded
But there were a couple of problems with that plan. While Hadoop and NoSQL were technologically impressive in some ways, they weren’t always easy to adopt and manage. The Silicon Valley tech behemoths that developed the new distributed frameworks that ran atop Hadoop–Apache Hive, Apache MapReduce, Apache Storm, etc.–had thousands of engineers on staff to make them work. That wasn’t always the case with the midsize retailers and manufacturers from the real world who bought into the idea that investing in the hot new technology would automatically give them an advantage.
Pretty soon, big data lakes were turning into big data swamps. Companies were finding out the hard way that storing a huge amount of data in Hadoop didn’t magically transform their operations. The devil, as usually, was in the details–details that were overlooked in business leaders’ haste to implement “the new new thing” and get ahead of the competition, or at least avoid falling behind.
IT analysts at Gartner warned that the majority of data lake projects would fail. They wrote about the “data lake fallacy,” and how taking shortcuts with data management would inevitably lead to bad outcomes. Not surprisingly, the original data lake vision resulted in lots of sunk costs. The whole Hadoop experiment began to unravel by about 2015. Some organizations eventually got Hadoop to work for them–heck mainframes are still roaming the land, decades after they were supposed to have died off–but the commercial market for Hadoop solutions essentially imploded in 2019.
Remnants of Hadoop technology still exist and are making meaningful contributions in business technology. The Hadoop Distributed File System (HDFS) and Hadoop’s resource scheduler, YARN, have essentially been replaced by S3-compatible object stores and Kubernetes, which forms the basis of the modern data stack. All of the cloud giants have successful big data offerings solutions on the market. And even some Hadoop-era technologies like Apache Spark, which replaced MapReduce, and Apache Iceberg, which corrects the data consistency problems created by Apache Hive, are thriving.

Bill Schmarzo, the Dean of Big Data
At the end of the day, however, it wasn’t a lack of technology that doomed the big data boom. Rather, it largely was traceable to the irrational belief that new technology, in and of itself, represented a viable business strategy. Otherwise rational business leaders were somehow convinced that investing in a certain technology could magically transform their businesses. In the real world, business transformation is a lot harder.
Bill Schmarzo was one of the most vocal supporters of the idea that there were no silver bullets, and that successful business transformation was the result of careful planning and a lot of hard work. A decade ago, the “Dean of Big Data” let this publication in on secret recipe he would use to guide his clients. He called it the SAM test, and it allowed business leaders to gauge the viability of new IT projects through three lenses.
- First, is the new project strategic? That is, will it make a big difference for the company? If it won’t, why are you investing lots of money?
- Second, is the proposed project actionable? You might be able to get some insight with the new tech, but can your business actually do anything with it?
- Third, is the project material? The new project might technically be feasible, but if the costs outweigh the benefits, then it’s a failure.
Schmarzo, who is currently working as Dell’s Customer AI and Data Innovation Strategist, was also a big proponent of the importance of data governance and data management. The same data governance and data management bugaboos that doomed so many big data projects are, not surprisingly, raising their ugly little heads in the age of AI.
Which brings us to the current AI hype wave. We’re told that trillions of dollars are on the line with large language models, that we’re on the cusp of a technological transformation the likes of which we have never seen. Jenson Huang, the CEO of the most valuable company on earth, has been dubbed “AI Jesus” for the important role Nvidia’s chips play in training AI models. We are just a few short years away from achieving the Holy Grail of AI: Artificial general intelligence, or AGI.
This all may prove to be true, or it may prove turn out to be another line in a long list of promising technologies that, for whatever reason, didn’t quite pan out as expected, and instead took some number of years to mature before providing real value to mainstream companies. There is evidence on both sides of the aisle. There is no denying that language models are demonstrating remarkable capabilities in areas like document understanding and programming. The potential to use AI to accelerate scientific discovery is tantalizing. However, we’re also seeing all-too-familiar warning signs of an overheated bubble.
Right on cue, Gartner in June published a warning that 40% of agentic AI projects were doomed to fail by 2027. Instead of rushing in on AI, Gartner recommends that agentic AI “only be pursued where it delivers clear value or ROI.”
Progress in AI is undeniable, but translating that progress into business success remains an elusive goal. The good news is that by lowering expectations, starting small, focusing on business fundamentals, and applying Schmarzo’s SAM test, business leaders will eventually figure out how to profitably use AI.
Related Items:
One Deceptively Simple Secret for Data Lake Success
Big Data Is Still Hard. Here’s Why
TPC25 Provides Glimpse at Future of AI-Powered Science
The post This Big Data Lesson Applies to AI appeared first on BigDATAwire.