

























VAST Fleshes Out Data Platform for Enterprise RAG Use Cases

VAST Data is quietly assembling a single unified platform capable of handling a range of HPC, advanced analytics, and big data use cases. Today it unveiled a major update to its VAST Data Platform engine aimed at enabling enterprises to run retrieval augmented generation (RAG) AI workloads at exabyte scale.
When solid state drives went mainstream and NVMe over Fabric was invented nearly a decade ago, the folks who founded VAST Data–Renen Hallak, Shachar Fienblit, and Jeff Denworth–sensed an opportunity to rearchitect data storage for high performance computing (HPC) at the exabyte level. Instead of trying to scale existing cloud-based platforms into the HPC realm, they decided to take a clean-sheet approach via DASE, which stands for Disaggregated and Shared Everything.
The first element of the new DASE approach with VAST Data Platform was the VAST DataStore, which provides massively scalable object and file storage for structured and unstructured data. That was followed up with DataBase, which functions as a table store, providing data lakehouse functionality similar to Apache Iceberg. The DataEngine provides the capability to execute functions on the data, while the DataSpace provides a global namespace for storing, retrieving, and processing data from the cloud to the edge.
In October, VAST Data unveiled the InsightEngine, which is the first new application designed to run atop the company’s data platform. InsightEngine utilizes Nvidia Inference Microservices (NIMs) from Nvidia to be able to trigger certain actions when data hits the platform. Then a few weeks ago, VAST Data bolstered those existing capabilities with support for block storage and real-time event streaming via an Apache Kafka-compatible API.
Today, it bolstered the VAST Data platform with three new capabilities, including support for vector search and retrieval; serverless triggers and functions; and fine-grained access control. These capabilities will help the company and its platform to serve the emerging RAG needs of its customers, says VAST Data VP of Product Aaron Chaisson.
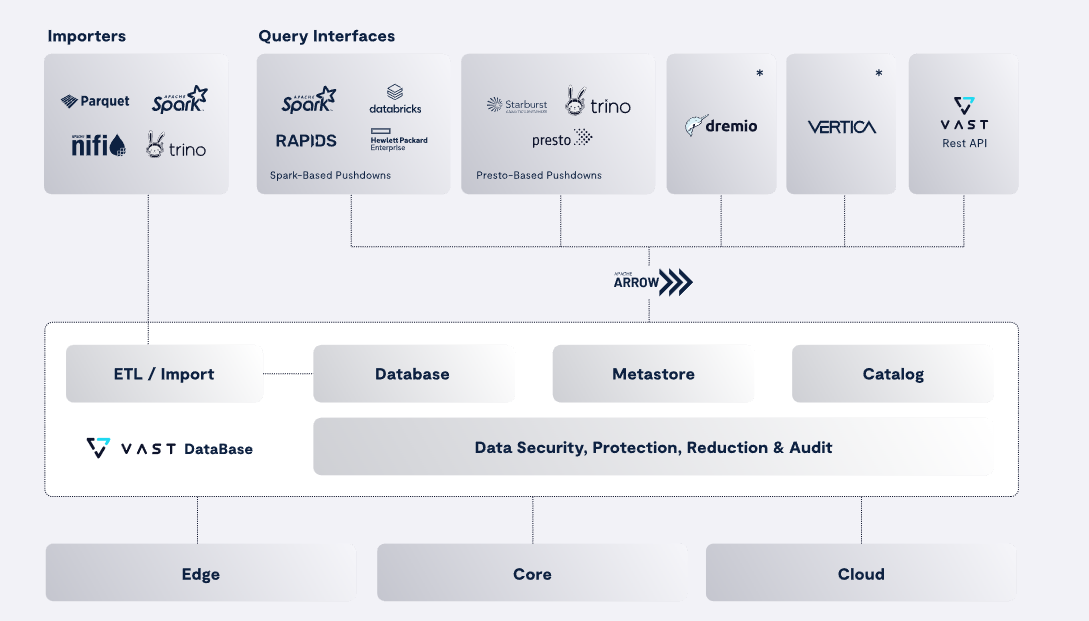
VAST DataBase was created in 2019 as a multi-protocol file and object store (Source: VAST Data)
“We are basically extending our database to support vectors, and then make that available for either agentic querying or chatbot querying for people,” Chaisson says. “The idea here was to be able to help enterprise customers really unlock their data without having to give their data to a model builder or fine-tune models.”
Enterprise customers like banks, hospitals, and retailers often have their data all over the place, which makes it hard to assemble and use for RAG pipelines. VAST Data’s new triggering function can help customers consolidate that data for inference use cases.
“As data hits our data store, that will trigger an event that will call an Nvidia NIM…and one of their large language models and their embedding systems to take that data that we save, and convert that into that vectorized state for AI operations.”
By creating and storing vectors directly in the VAST Data platform, it eliminates the need for customers to use a separate vector database, Chaisson says.![]()
“That that allows us to now store those vectors at exabyte scale in a single database that spreads across our entire system,” he says. “So rather than having to add servers and memory to scale a database, it can scale to the size of our entire system, which can be hundreds and hundreds of nodes.”
Keeping all of this data secure is the goal of the third announcement, support for fine-grained access control through row- and column-level permissions. Keeping all of this within the VAST platform gives customers certain security advantages compared to using third-party tools to manage permissions.
“The challenge that historically happens is that when you vectorize your files, the security doesn’t come with it,” he says. “You could end up accidentally having somebody having access to the vectors and the chunks of the data who shouldn’t have permission to the source files. What happens now with our solution is if you change the security on the file, you change the security on the vector, and you ensure that across that entire data chain, there’s a single unified atomic security context, which makes it far more secure to meet a lot of the governance and regulatory compliance challenges that people have with AI.”
VAST Data plans to show off its its capabilites at the GTC 2025 conference next week.
Related Items:
VAST Data Expands Platform With Block Storage And Real-Time Event Streaming
VAST Looks Inward, Outward for An AI Edge
The VAST Potential for Hosting GenAI Workloads, Data
The post VAST Fleshes Out Data Platform for Enterprise RAG Use Cases appeared first on BigDATAwire.












